5. Putting it all together
Now it’s time to take everything you’ve read and turn it into a plan. Your company’s size, age, culture, and capabilities guarantee that your situation is unique, so we’re limited in making hyper-specific recommendations. Still, there are some proven patterns in improving team delivery, rolling out an effectiveness effort more broadly, and avoiding the mistakes that most commonly derail these efforts.
This chapter covers three distinct but related topics. First, the most common failure modes we’ve seen in this work, so you can recognize the warning signs before the damage is done. Next, a practical approach to identifying and eliminating bottlenecks — work that any engineering manager can start today. Finally, a framework for sequencing an effectiveness effort across a broader organization, where the challenges shift from technical to political.
Where do you want to go?
Everything in this book up until now has helped you understand how to evaluate your current situation and the factors that impact effectiveness.
With a clear picture of where you stand and a framework for improvement, the next step is articulating where you want to go and what it will take to get there. These questions will deepen your understanding of how the four factors — size, age, culture, capabilities — come into play as you plan forward.
- What would “better” look like? Picture it: your engineering effectiveness investment was approved, it’s two years later, and things are working. You can’t believe you used to spend time doing … what? What changed to get you here? Now come back to today. If those changes are worth making, what’s stopping you from starting on them now?
- Who will champion the cause? Everyone benefits from more effective delivery — product, sales, customer support, engineering, users. The trickier question is: who will champion this work even when it comes at some near-term cost, like slower delivery of bug fixes and new features while you invest in foundations? Where will you find reliable allies?
- What kinds of potential changes are in scope? Does the company think of this as an engineering problem, a business problem, or both? What is the scope of the most senior person who will sponsor necessary change, even if it has a near-term cost? Who will warm up to the cause after a couple of success stories?
- What foundations need to be in place first? Are you trying to optimize a system that’s already reasonably healthy, or do you need to build foundational capabilities before optimization is even possible?
- What are the biggest obstacles you expect? This is not the time for rosy optimism. Talk openly, now, with anyone who wants to pitch in, about what’s going to be hard. Maybe two different engineering organizations aren’t aligned on what’s important; maybe you expect the CEO to defer to product priorities instead. Maybe everyone’s on the same page, but you worry that procurement will take three months. Maybe the real blocker is that you don’t have stable teams, and no tool will fix that. There are lots of ways this sort of effort can go sideways, so anticipate the ones you can.
What to avoid along the way
Even with the best intentions, engineering effectiveness efforts fail all the time. Understanding the most common ways they fail can help you avoid repeating mistakes that others have already made for you.
The big-bang rollout
It’s tempting to design an effectiveness program in its entirety, get buy-in from leadership, and then roll it out across the organization all at once. After all, you’ve done the research, you know what needs to change, and you want to show impact quickly. This almost never works.
Large-scale rollouts are fragile in ways that small experiments are not. When you change many things at once, you lose the ability to attribute outcomes to specific changes. When something doesn’t work — and something always doesn’t work — you don’t know which part to fix, so you’re left debugging your entire initiative instead of adjusting a single variable. Worse, a highly visible failure early in a big-bang rollout can undermine confidence in the entire effort, making it harder to try anything else afterward.
Small experiments are naturally safer. They produce learning at low cost, they’re easy to reverse when they don’t pan out, and — critically — their successes build the kind of evidence base that earns you trust for bigger changes later. A team that tries WIP limits for two sprints and sees their cycle time improve has a story to tell. That story is worth more than any slide deck when you’re trying to convince the next team to try it too.
This maps directly to the small batch sizes principle discussed in Chapter 3. Just as small code changes are easier to deploy, easier to debug, and easier to roll back, small process changes are easier to adopt, easier to evaluate, and easier to abandon without collateral damage. Treat your effectiveness effort the way you’d want your teams to treat their software: iterate, measure, adjust.
Communicating poorly — or too late
Of all the ways an effectiveness effort can fail, poor communication is probably the most preventable and the most destructive. It’s not simply that poor communication makes the effort harder. Poor communication can kill it outright, and the damage can persist for years.
Consider the scenario mentioned earlier: you show up one day and say, “We’re going to start measuring your work.” If engineers conclude that metrics are being used to surveil or punish them — even if that’s not the intent — the defensive reaction can be so strong that you’ve poisoned the well not just for this initiative but for the next several. Once that perception takes hold, no amount of subsequent reassurance will fully undo it.
The order of operations matters enormously. Build trust and communicate intent before anyone sees a dashboard. Explain the “why” before you show the “what.” And be prepared to keep communicating long after you think everyone has heard the message, because they haven’t. People absorb information at different rates, through different channels, and with different levels of skepticism. The first time someone hears about a change, they’re processing the fact that a change is happening. The second or third time, they might start engaging with the substance.
Transparency here means more than just sharing information. It means being honest about what you don’t know yet, being clear about what the metrics will and won’t be used for, and — perhaps most importantly — being willing to hear that people are uncomfortable and treating that discomfort as legitimate rather than as resistance to be overcome.
Letting metrics become the goal
You’ve probably heard some version of Goodhart’s Law: when a measure becomes a target, it ceases to be a good measure. This is an ever-present risk in engineering effectiveness work.
It usually starts innocently. You introduce DORA metrics to understand your teams’ delivery performance. A well-meaning leader sees the numbers and sets a goal: “Let’s get our deployment frequency to daily by Q3.” Now engineers are splitting deployments into smaller pieces — not because smaller batches are better, but because the dashboard needs to show a higher number. You’ve optimized the metric without improving the underlying capability, and you may have even made things worse by incentivizing behavior that doesn’t serve the actual goal.
The antidote is to treat metrics as conversation starters, not scorecards. When cycle time spikes, the right response isn’t to demand that it come back down. Instead, ask what happened and whether the spike represents a real problem or a reasonable response to circumstances. When deployment frequency drops, it might mean the team is struggling, or it might mean they’re doing a difficult migration that will pay off later. The metric can’t tell you which; only the conversation can.
Be especially cautious about setting numerical targets for effectiveness metrics, and be very cautious about tying them to performance evaluations. The moment an individual’s compensation or career progression depends on a metric, that metric will be gamed because people respond rationally to the incentives you create.
Conflating individual and team performance
This is related to the Goodhart’s Law problem but distinct enough to warrant its own entry. When you use effectiveness metrics — even informally or unintentionally — to judge individuals rather than teams and systems, two things go wrong: you mislead yourself about what’s happening, and you lose the trust you need to fix it.
Start with the measurement problem, because it’s the one that’s easiest to miss from where you sit. Individual performance is largely a function of the system around the person. Move an engineer from a struggling team to a healthy one and they can turn into a high performer; leave a strong team buried in years of unaddressed tech debt and the whole group can look like underperformers. Most of these metrics were built to describe systems, not people. The engineer on your team with the longest cycle time may be the one taking on the hardest problems — read that as a performance gap and you’ve got the story exactly backwards.
This is why the individual is rarely the lever you want to pull. The largest, most durable improvements come from changing the system and the team: clearing bottlenecks, fixing flaky infrastructure, rebalancing investment, improving how work flows. Every hour you spend comparing engineers to each other is an hour not spent on the changes that would move the numbers for all of them. The individual just isn’t where the leverage is.
Then there’s what it does to trust, which moves faster than you’d expect. The moment an engineer sees their personal commit count on a dashboard, they draw their own conclusions about what’s being measured and why — and no statement of good intent will override what the dashboard implies. Bring a metric like cycle time into a review as a personal scorecard, and you’ve taught the whole team that it’s something they’ll be judged on individually. What you get back is gamed numbers and defensiveness, and it’s hard to undo.
None of this means the data can never touch an individual conversation. In a team with psychological safety, looking at these numbers together can help you align on expectations and coach toward growth — and a shared, visible picture of the work is usually more honest than the version where complexity stays hidden behind a number nobody talks about. Used this way, the metric is context for a conversation, not the verdict. The catch is that this takes a level of safety most organizations don’t have, and it’s worth being honest with yourself about whether yours does. For most teams, even turning on transparency stings at first.
So here’s the default we’d suggest: put the weight of your measurement on systems and teams, where the leverage is. Individual data can inform a conversation, as one input among many, as long as you understand its limits — but it should never become the number someone is judged by. The further you drift toward ranking your engineers on these metrics, the more you mislead yourself and the more trust you spend.
Losing your champion
This might be the single most common way effectiveness efforts die at larger organizations. One senior leader cares deeply about the work, builds momentum, gets teams on board — and then gets promoted, moves to another part of the company, or leaves altogether. If the effort lived primarily in that person’s head and calendar, it can fall flat within a quarter. Teams that were mid-transition lose their air cover, priorities shift, and the institutional memory of why these changes mattered walks out the door.
The antidote is to build the effort into systems and processes rather than letting it depend on any single person’s attention. This means documented expectations, regular review cadences that are owned by teams rather than individuals, and — critically — making sure that more than one person at the leadership level understands and supports the work. If your effectiveness effort can’t survive you taking a two-week vacation, it’s too fragile to survive a real organizational disruption.
This also argues for investing early in the network of evangelists. When the champion leaves but a dozen engineers and managers across the organization have seen the benefits first-hand and feel ownership over the improvements, the effort has roots that go deeper than any one person’s tenure.
Importing someone else’s playbook
“This is how we did it at Google” is a powerful statement in a meeting, but a terrible basis for an effectiveness program. What worked at a company with a mature platform organization, tens of thousands of engineers, and a very specific engineering culture rarely translates directly to a company with different characteristics. The practices might be sound in principle, but the sequencing, tooling, and organizational context all matter.
This failure mode is especially common when a new engineering leader arrives from a well-known company and immediately begins replicating the systems they’re familiar with. Sometimes elements of that playbook are indeed applicable, but without understanding why they worked there and whether the same conditions even exist here, it can create confusion, wasted investment, and often a backlash that makes future changes harder.
The right approach is to treat outside experience as a source of hypotheses, not a blueprint. If a practice worked well somewhere else, that’s a reason to investigate whether it might work here, not a reason to immediately implement it.
Designing solutions without engineers in the room
The people whose work you’re trying to improve have strong opinions about what’s wrong and what would help. When an effectiveness program is designed entirely by leadership or a central team and handed to engineers as a finished plan, two things go wrong. First, it misses crucial context — the kind of ground-level knowledge that only comes from doing the work every day. Second, it misses the opportunity to give engineers ownership over the changes, and people are far more likely to support what they helped create.
This doesn’t mean every decision needs to be consensus-driven or that every engineer gets a vote on every process change. It means that the research, design, and prioritization of improvements should actively involve the people who will be affected. When engineers see their feedback reflected in the plan — when they recognize the pain points they described showing up as priorities — they become partners in the effort rather than subjects of it. When they don’t, they become skeptics, and skeptics are much harder to convert than collaborators.
The “we tried that already” immune response
Many organizations have been through previous improvement initiatives that fizzled, caused harm, or simply consumed a lot of energy without producing visible results. That history creates antibodies. When someone says, “We tried something like this two years ago and it didn’t work,” it can sound like resistance, but really, they’re sharing a data point that deserves to be taken seriously.
If you don’t acknowledge that history and explain what’s different this time, you’re fighting an opponent you can’t see. The people who lived through the last failed initiative remember the disruption, the unfulfilled promises, and the return to the status quo. They’re understandably skeptical that this time will be any different. Ignoring that skepticism doesn’t make it go away; it just makes it harder to address because people will express it to each other instead of to you.
So just be direct about it. Ask what happened before. Ask what went wrong and what, if anything, went right. Treat the previous attempt as useful data rather than something to be dismissed or papered over. Then, be clear and specific about what you’re doing differently, in concrete terms like “we’re starting with two teams instead of the whole organization” or “we’re measuring outcomes for six months before expanding.”
Improving on the team level
At Swarmia, we’ve seen time and again that when teams focus on improving just a few key areas, the payoff comes quickly. What follows is a team-level playbook: a set of areas where bottlenecks tend to hide, what to watch for, and what to start doing about them. This is work that a team and its manager can take on directly, starting now, without waiting for a broader organizational initiative.
- Workflow. What does the flow of work look like for your team? Does everything take forever, or do things normally go fine, with the exception of some worrisome outliers? Do you routinely finish the things you start? How much time does work spend in a waiting state?
- Priorities & WIP limits. Does your team have clear, stable priorities? How many things does your team work on at once? Is it generally obvious to software engineers what they should work on next? Do you feel like your team is too busy to ever do anything well?
- Keeping the lights on (KTLO). How much time does your team spend doing chores or fighting fires due to past decisions? How does this affect your ability to deliver predictably? How does it impact morale?
- Manual work and toil. What does the team do manually on a somewhat predictable basis and why? Are your tests, deployments, and rollbacks all automated? Does your team planning include time to automate these tasks regularly?
- Decisions owned outside the team. How often does the team need to wait for an outsider decision to make progress with their own work?
Here’s a closer look at each area, what it looks like when you have bottlenecks, and what to start doing today to get things on a better path.
| Aspect | What to watch for | What to start doing today |
| Workflow | Consistent delays in task completion. Certain types of tasks are routinely blocked. Unpredictable delivery. | Track cycle times and change lead times for your code changes and issues (task, story, epic, bug, etc.). Track the time engineers spend waiting on CI/CD. Track the time work is left waiting or idle. |
| Priorities & WIP limits | More work in progress than members on the team. Overwhelmed engineers. Frequent changes in priorities. Unfinished work. | Set a WIP limit for roadmap projects/stories, starting with the number of devs in the team divided by 2. Learn how to collaborate and plan work in a way that allows multiple engineers to work on a larger roadmap item. Only allow a higher WIP limit when workflow metrics are not ballooning because of the change. Maintaining some “slack” in your capacity increases your ability to deliver faster. Aim for 75–85% utilization of your team (not 100%) to preserve the team’s productivity. |
| KTLO & reactive work | KTLO consumes more than 30% of a team’s time. Incidents cause frequent disruptions to focused work. Team goals are routinely delayed due to lack of slack to handle reactive work. | Track change fail rate to understand quality. Track engineering investment according to the Balance Framework, explained in Chapter 2. If a team is spending more than 30% of its capacity on KTLO and reactive work, consider whether this could be reduced by prioritizing work that improves quality, customer support (discussed in Chapter 4), or developer productivity. If prioritizing that work isn’t practical, consider whether the team is the right size for the surface it owns. |
| Manual work and toil | Recurring manual tasks are time-consuming and error-prone. Deployments require human attention. | Automate CI/CD and deployments. Create a culture where quick automations just get done without extensive discussion. Check your investment balance to make sure you always invest at least 10% of your capacity in productivity improvements. Encourage and incentivize conversations about productivity improvements. |
| Decisions owned outside the team | Work stalls while waiting for external input. Poor sequencing of dependencies. Top-down priority changes. | Consider the guidance in Chapter 2 about organizing teams and making tradeoffs. Are the tradeoffs you made still the right ones? Ensure your team has the skills it needs to operate effectively without requiring regular technical assistance. Quantify the impact of processes that are external to your team in terms of wait time, effort, and interruptions. Establish visibility into the progress of cross-team initiatives. |
Finding opportunities in these areas is usually painfully straightforward, and chances are good that engineers in your organization already have strong ideas about what to do. Acting on those opportunities will require finding ways to invest in the time and culture needed to implement solutions now and moving forward.
Generally, be wary of claims that more processes will make things go faster, and be skeptical when someone suggests a headcount fix (unless they’re advocating for staffing a platform team) — more people rarely mean more output over the short term. Remember, any proposed fix that changes the size, shape, or remit of a team can affect productivity — positively or negatively — for months.
Know when to move on
As one bottleneck is addressed and resolved, it ceases to be the limiting factor in your workflow. The new bottleneck is in another area of the process. At this point, it’s time to move from actively working on the first bottleneck toward monitoring it to ensure there’s no backsliding.
By continuously moving the focus to the current bottleneck, you maintain a steady flow in your processes. Identifying, addressing, and monitoring bottlenecks is an ongoing process — and it’s just one part of an overall effort at continuous improvement.
Improving on the organizational level
The bottleneck work described above is something any team can do on its own, starting today. What follows from here is a framework for when you’re ready to drive improvement across a broader organization. The challenges shift from identifying what to fix to orchestrating how and when to fix it, earning trust along the way, and sustaining the effort over time.
Implementing an engineering effectiveness program is no small feat, and thoughtfully sequencing your approach will increase your chances of success. Here, we sketch a roadmap to guide you on this journey, broken down into six key stages: baseline, research, act, invest, normalize, and sustain (or BRAINS, for a memorable acronym).
Before we get into the stages, a word about how to read this framework. These stages are sequential in the sense that you need to understand your current state before you can act on it, and you need early wins before you can (or should) justify larger investments in new ways of working. But in practice — especially in larger organizations — you’ll find yourself in multiple stages simultaneously, with different teams at different points in the progression. You might be baselining one part of the organization while normalizing changes that are already working well in another. That’s fine.
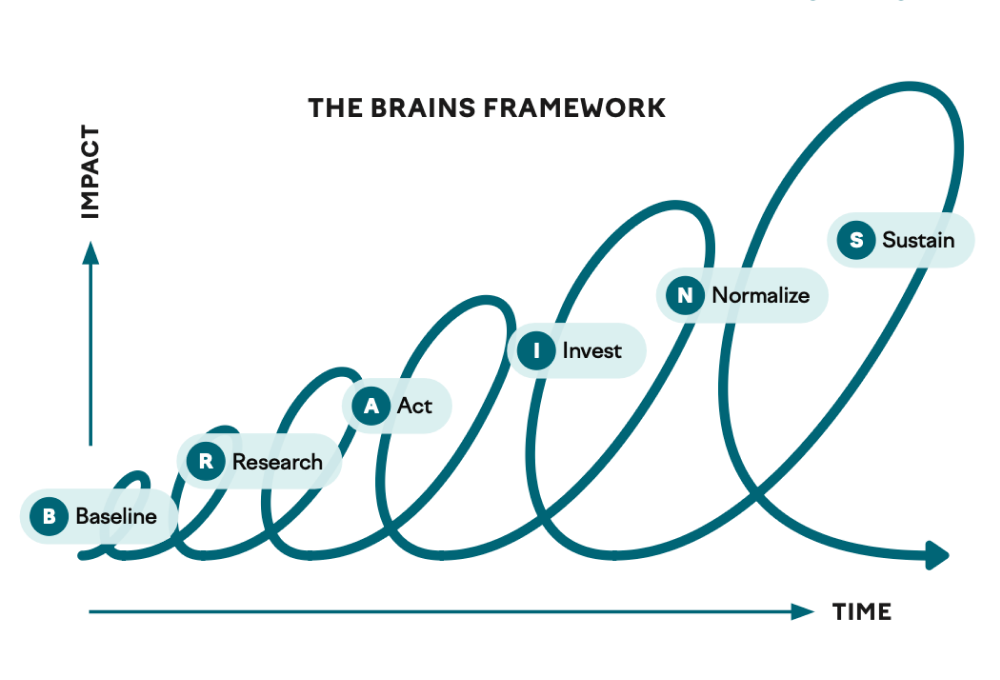
One principle cuts across every stage: start small and earn the right to go bigger. This isn’t just a platitude about managing risk. In a larger organization, an effectiveness effort lives or dies on its credibility, and credibility is built through demonstrated results. Every stage should produce something concrete that you can point to — a measurable improvement, a team that’s working better, a process that’s less painful — and those proof points become the foundation for everything that follows.
Baseline
The first step is understanding your current situation, and the temptation is to try to understand everything at once. Resist this. At a large organization, a comprehensive baseline of every team’s delivery performance, tool ecosystem, and developer experience could take months — and produce a report that’s outdated before it’s finished. Instead, focus your initial baseline on a manageable scope: a few teams, a single product area, or a specific part of the delivery pipeline. Go deep rather than broad.
Start from the table stakes identified in Chapter 1 (for organizations) and Chapter 3 (for teams). Does your organization uphold and support these table stakes? If not, as mentioned earlier, there will be a ceiling on the improvement you can achieve.
Take an inventory of the delivery-related metrics you have today and identify useful ones that would be easy to add. Assess team health by looking at satisfaction, attrition rates, and engagement levels. If you’re still small, this should happen organically; once you’re larger than 10 engineers, you may also want to create more intentional feedback mechanisms. Paint a picture of where things stand today — for yourself and your stakeholders.
This is also a good time to consider implementing DORA metrics that accurately represent your software delivery performance. Getting these in place requires some discipline and the right systems, but you’ll be glad you did it. The same goes for attaching Balance Framework labels to your work items — start building that picture of where your time is actually going. You may want to build or buy a tool that makes this easier. It’s another practice you’ll thank yourself for later.
There are two things to keep in mind during this stage. First, the goal is not to create benchmarks for comparing teams or individuals — it’s to understand the present state so you can track improvement over time. Make this explicit early and often, because people will assume the worst if you don’t. Second, if you’re working within a larger organization, identify the teams most likely to be willing early partners. You want teams whose leaders are curious about improvement and whose engineers are open to trying new things. These teams will become your proof-of-concept partners in the next stage, and eventually, your most compelling evangelists.
Research
Knowing how your engineering teams experience their work is essential to making real progress on engineering effectiveness. This is where you move beyond metrics and into the lived reality of how software gets built at your organization.
Spend time shadowing engineers, conducting interviews, running surveys, and doing hands-on work. Understand their daily challenges, frustrations, and moments of triumph. Pay particular attention to their work patterns, collaboration habits, and pain points. Watch for systemic issues that might be slowing them down or creating unnecessary stress. This first-hand understanding is invaluable when it comes to identifying improvements that will actually stick.
Now is also the time to review your early Balance Framework data. Where are teams spending their time? Are there any surprises? What adjustments need to be made?
In a larger organization, the research stage serves a second purpose: it builds relationships. When you sit with engineers and truly listen to what’s frustrating them, you’re doing more than gathering data. You’re establishing yourself as someone who understands their reality — and giving them a reason to trust that the changes you propose later are grounded in actual problems rather than theoretical frameworks. These relationships matter enormously when it comes time to drive adoption.
At this stage, you should also start identifying potential evangelists — people at various levels of the organization who share your conviction that things could be better and have the credibility to influence their peers. These aren’t necessarily the most senior people; often, the most effective evangelists are well-respected individual contributors or engineering managers whose teams are already performing well. You’ll need them later, so start investing in those relationships now.
Act
Now that you understand your engineers’ current state and unique needs, it’s time to tackle the quick wins. These are small, relatively easy improvements that nonetheless have a meaningful impact on the daily work of your teams — streamlining a standard process, eliminating a manual task, addressing a common source of frustration.
Quick wins serve a dual purpose. They make things better for the people affected, and they demonstrate that your effectiveness effort produces tangible results. In a larger organization, that second purpose is at least as important as the first. Every quick win is a proof point you can use to build support for more ambitious work, and every team that benefits becomes a potential advocate. Don’t underestimate the power of an engineer telling their colleague in another group, “Hey, we tried this and it actually helped.”
Who’s going to work on these quick wins? For now, make sure every engineer knows they have permission to spend a little time making things better. Consider giving an engineer or two a few weeks on a rotation to tackle something they’re passionate about. Celebrate both large and small improvements publicly, and publicize the biggest opportunities.
Nothing erodes credibility faster than asking people to share their frustrations and then visibly ignoring them.
One critical principle at this stage: do what you said you’d do. If you told engineers during the research phase that you’d address a specific pain point, address it — or explain clearly why you can’t and what you’re doing instead. In a smaller organization, you might get away with a missed commitment because people can see your constraints first-hand. In a larger organization, the person you made a commitment to may be several layers of management removed from you, and all they’ll remember is that you asked, they answered, and nothing changed.
Invest
With the low-hanging fruit addressed, it’s time to focus on longer-term improvements at the organizational level. This often involves standardizing processes and tools across teams to reduce complexity and inconsistency.
Consider creating a dedicated platform team responsible for developing and maintaining shared tools and infrastructure. Starting a team doesn’t have to be a big production; the team lead already works at your company and is looking for a new opportunity. They’re the self-directed, consistently high-impact person who’s been poking at flaky tests and exceeded expectations last quarter by automating the entire build and deployment. They’re a favorite collaborator among technical and non-technical folks alike, and they live for a good session of code archaeology. The second engineer is also a colleague, and they were exceeding expectations within their first months. They’re a smart execution machine in need of a good mentor — interested in humans and computers, hungry for challenging problems, and unbothered if people in the real world don’t see their work.
This team will be most successful if they think of internal engineering platforms as products, and understand that products have users — users you need to talk to and listen to, especially when they’re frustrated. A platform team’s ultimate goal is to help those users produce more value for the same amount of effort.
In a larger organization, the invest stage is where you’re most likely to run into political complexity. Standardization implies that some teams will need to change how they work, and those teams may have legitimate reasons for doing things differently — or they may simply be attached to their current approach. This is where your proof points from the act stage become essential. If you can show that Team A improved their cycle time by 30% after adopting a standardized deployment pipeline, Team B is more likely to consider the same change. If all you have is a theoretical argument for standardization, you’ll spend most of your time in meetings debating hypotheticals.
This is also the stage where you need to be explicit about any new expectations. If you’re asking teams to adopt new tooling, follow new processes, or report on new metrics, document those expectations clearly. Ambiguity here creates resentment later, when people discover they were supposed to be doing something they didn’t know about. If you want teams to label their work items with Balance Framework categories, write it down. If you expect teams to maintain a certain level of test coverage before deploying, write it down. If there’s a new code review process, write it down and make it easy to find. People can adapt to clear expectations far more readily than to expectations they have to guess at.
Normalize
Standardization only delivers its full benefits when it becomes the default — and making something the default across a large organization is one of the hardest things you’ll do in this work.
The goal is to create happy paths for common development tasks, like adding a new API endpoint or building a new feature in the user interface. Drive adoption of these new processes until they’re just how things are done. That requires clear communication about what’s changing and why, solid training so that everyone knows how to work within the new systems, and enough support to make the transition feel manageable rather than disruptive.
Stay close to development teams throughout this period and stay open to feedback. You can form an adoption squad to help teams make the transition and understand the benefits. Automate wherever you can. Where you can’t, make sure migration and usage instructions are written from the perspective of the platform user — not the platform creator.
At a smaller company, normalization might happen over a few weeks as word spreads organically and people adopt new practices, because they can see their neighbors benefiting. At a larger company, it’s a sustained campaign that can take quarters. It’s expected that different parts of the organization will move at different speeds. Some teams will adopt eagerly because they were involved early and already trust the process. Others will be skeptical — either because they haven’t seen the proof points first-hand, or because they’ve been burned by past initiatives that promised improvement but only delivered disruption.
This is where your network of evangelists pays off. A recommendation from a respected peer carries more weight than a mandate from a central team, and an engineer who can say “we’ve been doing this for three months and here’s what changed” is more convincing than any documentation. Invest in enabling these evangelists: give them data to share, bring them into planning conversations, and make sure they’re recognized for the role they play.
The temptation during normalization is to resort to mandates when voluntary adoption stalls. Sometimes mandates are necessary, but they should be a last resort — and when you use them, be transparent about why. A mandate that comes with a clear rationale, adequate support for the transition, and a willingness to hear feedback is very different from one that arrives as a decree from on high.
Sustain
Maintaining and improving engineering effectiveness is not a one-off task. As your company grows, so will the complexity of the challenges you’re trying to solve. Keep investing in your understanding of those evolving challenges and stay open to new approaches. Set strategic goals that reflect this commitment and build a culture of continuous learning.
The focus here is on the overall health of your engineering organization — not on specific tactics or short-term wins. Keeping that in mind will help you stay adaptable as your teams’ needs change.
In a larger organization, sustaining an effectiveness effort means building it into the organizational fabric so it doesn’t depend on any single person’s attention or enthusiasm. The champion who launched the effort might move to a different role; the executive sponsor might leave the company; the team that was most enthusiastic early on might shift priorities. If the effort is sustained only by individual commitment, it will fade. If it’s sustained by systems — regular retrospectives, ongoing metric reviews, a platform team with a clear mandate, documented expectations that new teams inherit — it has a much better chance of persisting through organizational change.
This is also the stage where honesty matters most. After months or years of effort, it’s natural to want to declare victory and move on. However, the reality is that some things you tried won’t have worked, some improvements will have eroded, and new problems will have emerged that didn’t exist when you started. Your organization is much more likely to sustain effectiveness over time if you can look honestly at where you still fall short. Treat this as a natural part of the work, not a sign that the initiative failed.
What’s next?
If you’ve made it this far in the book, you now have a set of tools and frameworks that most software engineering organizations lack. You understand how to think about business outcomes, developer productivity, and developer experience as interconnected concerns rather than competing priorities. You have a vocabulary for talking about bottlenecks, a framework for sequencing an improvement effort, and a catalog of failure modes that can help you recognize trouble before it becomes entrenched.
That’s a pretty significant advantage. Most engineering organizations fail at this because they lack a coherent way to think about the problems, talk about them with stakeholders, and act on them systematically. You now have that.
The work ahead will still be hard. You’ll encounter resistance, make wrong calls, and discover that some of your best ideas don’t survive contact with your organization’s reality. That’s normal. Lasting effectiveness comes from building the habit of paying attention, adjusting, and trying again — not from getting everything right the first time.
So start where you are, today. If you’re an engineering manager with a single team, start with the bottleneck identification work and see what improves. If you’re an engineering leader with a broader mandate, use the BRAINS framework to sequence your approach and build credibility through early proof points. Whatever your scope, keep the focus on the ultimate goal: improving the experience and productivity of your engineers in ways that produce better outcomes for the business and its users.
Every organization and team is unique, and your path will look different from anyone else’s. This isn’t a limitation, but the nature of the work. Remain flexible, stay honest about what’s working and what isn’t, and remember that your effort will compound over time in ways that aren’t always visible in the moment.
Further reading
- Leading Change, by John P. Kotter. Kotter provides an eight-step process for leading change with powerful insights and practical tools.
- The Goal: A Process of Ongoing Improvement, by Eliyahu M. Goldratt. This book introduces the Theory of Constraints — a methodology for identifying the most important limiting factor (i.e. bottleneck) in a process and systematically improving it.
- Switch: How to Change Things When Change Is Hard, by Chip Heath and Dan Heath. Offers insights into how to effect transformative change in organizations, which is useful for understanding and managing the human side of organizational change.
- Lean Thinking: Banish Waste and Create Wealth in Your Corporation, by James P. Womack and Daniel T. Jones. Provides a deep dive into lean principles, focusing on eliminating waste and improving efficiency, which are key to addressing process bottlenecks.
- Crucial Conversations: Tools for Talking When Stakes Are High, by Kerry Patterson, Joseph Grenny, Ron McMillan, and Al Switzler. Valuable insights into handling high-stakes conversations.